在当今数据驱动的时代,无论是大型电商平台的秒杀活动,还是社交媒体平台的实时信息流,亦或是金融科技的高频交易,都对后端数据库服务提出了前所未有的挑战:高容量的数据存储与高并发的访问处理。传统的单机或主从架构数据库在TB/PB级数据量和每秒数十万甚至百万级TPS(每秒事务处理量)面前已力不从心。因此,构建一个健壮、可扩展、高性能的数据库分布式架构,成为支撑现代互联网业务的核心基石。本文将从一个技术专家的视角,深入解读高容量大并发数据库服务背后的分布式架构设计思想、关键技术选型与核心挑战。
一、核心挑战与设计目标
在设计高容量大并发数据库服务之初,必须明确其面临的核心挑战:
- 容量瓶颈:单台服务器的存储(磁盘)、内存和计算(CPU)资源有限。
- 性能瓶颈:单点处理能力无法应对海量并发读写请求,连接数、锁竞争、I/O等待成为瓶颈。
- 可用性风险:任何单点故障都可能导致服务不可用,无法满足99.99%甚至更高的SLA(服务等级协议)。
- 扩展不灵活:传统架构下,垂直扩展(Scale-Up)成本高昂且存在上限,难以应对业务的快速增长与波动。
因此,分布式架构的设计目标清晰而统一:可扩展性(Scalability)、高可用性(High Availability)、高性能(Performance)和易维护性(Maintainability)。
二、分布式架构的核心设计思想
为了达成上述目标,现代数据库分布式架构通常围绕以下几个核心思想展开:
1. 数据分片(Sharding/Partitioning)
这是解决容量和写并发问题的根本方法。将整个数据集水平拆分,分散到多个数据库节点(分片)上。
- 分片键选择:至关重要,需选择能均匀分布数据且频繁用于查询的字段(如用户ID、订单ID)。选择不当会导致“数据倾斜”,部分分片负载过重。
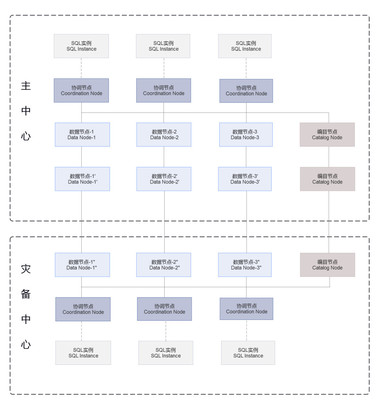
- 分片策略:常见的有范围分片、哈希分片、一致性哈希等。哈希分片能保证数据均匀分布,但范围查询困难;一致性哈希在节点增删时能最小化数据迁移。
- 分片位置透明性:对应用层最好屏蔽分片细节,由独立的中间件(如ShardingSphere、Vitess)或数据库原生能力(如MongoDB、CockroachDB)负责路由。
2. 读写分离与副本集(Replication)
这是提升读并发能力和可用性的关键。
- 主从复制:一个主节点(Master)负责写操作,多个从节点(Slave)异步或半同步复制主节点数据,负责读操作。这极大地分摊了读压力。
- 多副本高可用:采用一主多从,甚至多主多从架构(如MySQL Group Replication, Galera)。当主节点故障时,能通过选举机制快速自动切换(Failover)到健康的从节点,保证服务不间断。
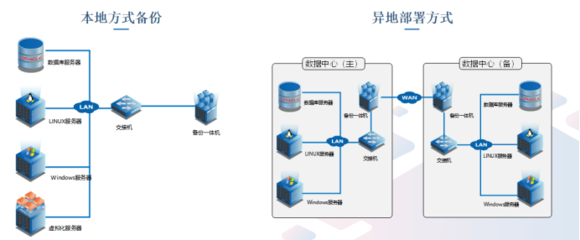
- 全球分布式部署:在异地数据中心部署副本,既能实现地理级别的容灾,也能让用户就近读取数据,降低访问延迟。
3. 分布式事务与一致性
这是分布式架构中最复杂的一环。当一次操作涉及多个分片时,如何保证ACID特性?
- 强一致性模型:如使用两阶段提交(2PC)协议,但性能开销大,存在阻塞风险。Google Spanner通过TrueTime API和Paxos协议实现了全球分布式下的强一致性,但架构极其复杂。
- 最终一致性模型:这是互联网分布式系统更常见的选择。通过消息队列、异步补偿、版本向量等技术,在确保系统高可用的前提下,允许数据在短暂时间内不一致,但最终会达成一致。这需要业务逻辑有一定的容错能力。
- NewSQL的探索:如TiDB、CockroachDB等NewSQL数据库,尝试在分布式环境下同时提供水平扩展、高可用和强一致性(或跨行ACID事务),是当前的技术热点。
4. 弹性伸缩与无状态化
为了应对流量的潮汐效应,理想的架构应能实现弹性伸缩。
- 计算与存储分离:将数据库的计算层(SQL解析、优化、执行)与存储层(数据持久化)分离。计算层可以轻松地水平扩展以应对并发请求,存储层则可以独立扩展容量和IOPS。云数据库(如AWS Aurora、阿里云PolarDB)是这一架构的典范。
- 无状态计算节点:计算层节点不持久化用户数据,任何请求可以被任何计算节点处理。这使增加或减少计算节点变得非常简单快速。
三、关键技术选型与典型架构模式
1. “中间件+传统数据库”模式
- 架构:使用独立的代理中间件(如MyCAT、ShardingSphere-Proxy)对应用层提供统一的SQL入口,中间件负责SQL解析、路由、结果聚合等。后端是多个分片的MySQL/PostgreSQL实例组(主从架构)。
- 优点:技术栈成熟,对现有业务侵入小,可充分利用传统数据库的生态和工具。
- 缺点:架构复杂,运维成本高;中间件可能成为新的性能瓶颈和单点;分布式事务支持弱。
2. 原生分布式数据库
- 架构:直接采用为分布式而生的数据库系统,如TiDB(兼容MySQL协议)、CockroachDB(兼容PostgreSQL协议)、MongoDB Sharded Cluster、Cassandra等。
- 优点:开箱即用的分片、复制、故障转移和(某种程度的)分布式事务能力,整体运维复杂度相对较低。
- 缺点:可能存在生态工具不如传统数据库丰富,特定场景下性能或功能有取舍,有被厂商锁定的风险。
3. 云原生数据库服务
- 架构:直接使用云厂商提供的全托管数据库服务,如AWS Aurora、Google Cloud Spanner、阿里云PolarDB for MySQL。
- 优点:极致简化运维,自动备份、扩缩容、故障恢复;通常采用计算存储分离、日志即数据库等先进架构,提供极高的性能和可用性。
- 缺点:成本较高,跨云迁移困难,深度定制能力受限。
四、实践建议与
- 评估为先:不要为了分布式而分布式。首先明确业务的数据量、并发量、延迟和一致性要求。很多场景下,一个优化良好的单机数据库加上读写分离和缓存(如Redis)就足以应对。
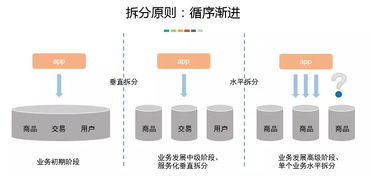
- 渐进式演进:架构演进路径可以是:主从复制 -> 读写分离+缓存 -> 垂直分库(按业务拆分)-> 水平分片(按数据拆分)。
- 监控与可观测性:在分布式环境中,完善的监控(资源、性能、慢查询)和链路追踪(Trace)是快速定位问题的生命线。
- 拥抱云原生:对于大多数企业,从效率和成本角度考虑,直接采用成熟的云数据库服务可能是最优解,可以将精力聚焦于业务创新。
总而言之,设计高容量大并发数据库服务的分布式架构,是一场在一致性、可用性、分区容错性(CAP定理) 之间,以及在性能、复杂度、成本之间寻求最佳平衡的艺术。没有银弹,只有最适合当前业务发展阶段和技术团队能力的方案。随着软硬件技术的不断发展,特别是云原生和NewSQL的成熟,构建和维护此类系统的门槛正在逐步降低,但其核心的设计思想与权衡智慧,始终是每一位技术架构师需要深刻理解和掌握的。